

For Marist Artificial Intelligence, my buddy Phil and I had to make a Chess AI. The professor hosted a server that would manage teams and a 2D display of games. AIs had to manage gamestates and submit moves to the server, as well as receive new moves when it wasn’t the AI’s turn. The server managed whether moves were valid or not and would update the 2D display when the AIs submitted their turn. After several weeks of development, all the teams competed their AIs against each other.
And we won!
Read on to learn about our AI.
To put it lightly, our Chess AI pretty much crushed the competition. To everyone else’s credit, we put a lot more time into our AI than most other teams which was why. We implemented tons of features such as dynamic depth searching, Quiescence extensions, and a sophisticated evaluation of gamestates.

The winner of the AI tournament then went on to play the best chess player at Marist. Our AI even won against a really good human player! However, to his credit, he gave our AI a run for its money and probably would win if he played again. It was interesting watching our evaluation function each turn spitting out really even numbers against the human player the whole time.
Our Github repo is available here. More information about the Chess AI algorithms and its code can be found in the readme.
I saved the tournament finales so you can also checkout our WebGL Chess Visualizer! That was our Graphics class project from the year prior to making the AI.
- To view the final AI tournament game, just press ‘Connect’.
- To view the AI vs Human game, dropdown and select AI vs Human, then press ‘Connect’.
- If you’re familiar with our professor’s server, you can also uncheck the “GameID” box in the GUI and input game IDs such as http://bencarle.com/chess/cg/849 (where 849 is the ID).
I learned a lot doing this project. The different methods of searching and ways to prune results out I find to be pretty fascinating. Even such a widely researched topic for decades doesn’t have a “perfect” answer. We did a lot of reading about Deep Blue and different ways to efficiently speed up the code. I started a basic Negamax function, and we evolved it iteratively. Phil took the Negamax and made it into a NegaScout along with multithreaded pruning. Phil also implemented a dynamic depth that estimates the time for various depths, with some offsets for various game-times, and the AI will boost the search if it needs to. The tournament, by the way, was timed moves.
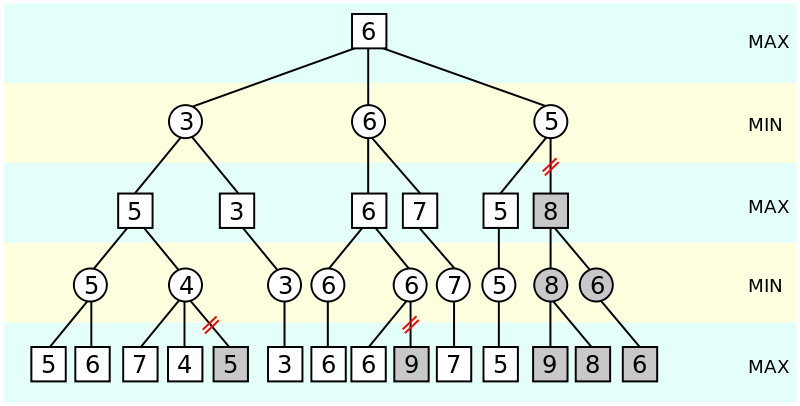
The evaluation function for the search included many different considerations such as doubled/isolated pawns, piece tables, material value, and fixed bonuses for various game-times like late end game. It is a linear search over the table, and has to be done whenever the NegaScout hits a leaf, so speeding up this function is an example of the 80/20 programming rule along with the search itself.
So to try to speed up the search and evaluation, we attempted to do Zobrist powered Transposition tables. But after several days of effort, we abandoned it because it felt like the speed increase was negligible compared to the multithreaded search. The tables were in 2 parts… Zobrist keys were basically keys to the hashtable that we would store alpha/beta results in. The keys were randomly generated 256SHA numbers that would have the gamestate (after every move applied) XOR’d in. So if a pawn was moved from one spot to another, the board “key” would incrementally have a pawn XOR’d out and into respective spots. Then that key could theoretically be used to uniquely look into a table of evaluations, allowing you to skip evaluatiing the board every time while searching for the best move. However, even with a 3-4GB table, it didn’t speed up our search. Moves would play about roughly the same without the tables, but nothing revolutionary. There is a chance we were doing the table itself wrong, but the payoff just wasn’t obvious to us for the amount of debugging.
At one point we even booted up a 16 core Azure server and ran the AI on there too! But, interestingly enough, there wasn’t great scaling. It showed no real improvement, because more threads than available work existed. Thus, a good lesson about threads.
I would say if I had to go back and change anything, it would be to have spent less time on Transposition and more implementating strategy. We don’t do mobility checks except for the King, particularly because how much processing that would take for each move. When I considered it, we were so deep that it had more chance of introducing bugs than it would pay off for in the long term, similar to the Transposition tables. So I would’ve liked to have done that early on. I also would have reconsidered some of the structure of the program, such as the way GameState exists when there realistically would never be more than 1 GameState during run time. I also would’ve liked to have done this in C++ to really pull some speed out of searching, but we decided to run C# because Phil was more familiar with that, and .NET would be more compact to do stuff like multithreading (aka not having to bother with boost in C++ and just run with provided .NET libraries).
Our end result was Bunduru AI taking up ~3.5MB of memory, supporting multithreading, dynamically do searching up to depth 11 reasonably in end game, can play either black or white, and won the Marist chess tournament!
In case you were wondering why we named the Chess AI and Visualizer “Bunduru”…